

In today’s hyperconnected business environment, incidents are no longer a question of if but when. From system outages and operational disruptions to security breaches and service failures, even a single unresolved incident can cascade into financial loss, reputational damage, and customer dissatisfaction. This is why incident management has emerged as a critical discipline—one that enables organizations to respond swiftly, minimize impact, and restore normal operations with confidence.
The cost of ineffective incident management is staggering. Industry estimates show that system downtime can cost organizations millions of dollars per hour, depending on scale and sector. More alarmingly, research reveals that it takes an average of 204 days to detect a security breach, giving threats ample time to escalate. Despite these risks, only about 55% of organizations have a documented incident response plan, and many fail to review or update these plans regularly—leaving critical gaps during high-pressure situations.
Incident management provides a structured framework to identify, log, prioritize, resolve, and learn from incidents. It goes beyond firefighting by emphasizing accountability, clear communication, and continuous improvement. When executed effectively, incident management not only reduces downtime and operational risk but also strengthens organizational resilience and stakeholder trust.
Modern ERP platforms can play a meaningful role in supporting incident management processes. Deskera ERP helps organizations centralize data, streamline workflows, and improve visibility across operations. With integrated modules for finance, operations, customer support, and reporting, Deskera enables faster issue tracking, better coordination across teams, and data-driven insights that support timely incident resolution. By embedding incident-related workflows within everyday business systems, organizations can respond more effectively while maintaining operational continuity.
What Is Incident Management?
Incident management is the structured process used by IT operations and DevOps teams to respond to unplanned disruptions that affect normal business operations. These disruptions—known as incidents—can range from system outages and application slowdowns to cyberattacks, network failures, or even a single user being unable to access a critical service. The primary goal of incident management is to restore normal service as quickly as possible, while minimizing business impact, financial loss, and reputational damage.
Modern businesses rely on a tightly interconnected digital ecosystem to function smoothly. However, this same interdependence increases risk—one failure can trigger widespread disruption in seconds. Incident management provides organizations with a reliable way to detect issues early, respond efficiently, and prevent minor problems from escalating into major outages. When executed well, it helps reduce downtime, protect data, and ensure continuity across business operations.
At its core, incident management focuses on rapid response and service restoration, not long-term fixes. An incident is considered resolved once the affected service returns to its intended state, even if deeper root-cause analysis happens later. Incidents can vary widely in severity—from a global service outage affecting thousands of users to intermittent performance issues impacting a small team—but all require prioritization, coordination, and clear ownership to limit disruption.
Incident management is a foundational practice within the ITIL (Information Technology Infrastructure Library) framework, which is widely adopted for IT Service Management (ITSM). According to ITIL, an incident is any unplanned interruption to an IT service or reduction in service quality, and the objective of incident management is to restore service quickly while maintaining agreed service levels. Originally rooted in the IT service desk, incident management has evolved beyond basic user support into a strategic capability—one that supports continuous improvement, system reliability, and consistent service availability in complex, always-on environments.
In essence, incident management equips teams with a clear plan to respond decisively, communicate transparently, collaborate effectively, and learn continuously—turning unexpected disruptions into opportunities to strengthen systems and processes for the future.
Common Types of IT Incidents in Incident Management
Not all IT incidents have the same cause, severity, or business impact. Some disruptions bring operations to an immediate halt, while others degrade performance gradually and go unnoticed until they escalate.
Understanding the most common types of IT incidents helps organizations prepare appropriate response strategies, prioritize resources effectively, and reduce the overall impact on service quality and customer experience.
Hardware Failures
Hardware-related incidents include issues such as hard drive crashes, server overheating, power supply failures, or faulty network equipment. These incidents can cause sudden service outages and require rapid detection, replacement, or failover mechanisms to restore operations and prevent prolonged downtime.
Software Bugs and Application Errors
Software incidents often arise from coding errors, faulty updates, or failed deployments. Applications may crash, behave unpredictably, or slow down significantly. Quick triage, rollback plans, and patch management are essential to stabilize services while teams investigate and resolve the underlying issue.
Network Outages
Network-related incidents disrupt connectivity to business-critical systems and services. These may result from firewall misconfigurations, ISP outages, bandwidth congestion, or DNS failures. Resolving network incidents often requires close coordination between internal IT teams and external service providers to restore stable access.
Security Incidents and Breaches
Security incidents such as phishing attacks, malware infections, ransomware, or unauthorized access attempts are among the most high-risk IT incidents. They demand immediate containment, thorough investigation, and remediation to protect sensitive data, maintain compliance, and restore trust with customers and stakeholders.
Human Errors
Many IT incidents are caused by human mistakes, including misconfigurations, accidental data deletions, or missed system updates. While these incidents are common, they are also highly preventable through strong change management practices, access controls, and standardized procedures.
Service Performance Degradation
Not all incidents result in full outages. Slow response times, intermittent errors, or reduced system performance can still significantly impact productivity and user experience. These incidents require proactive monitoring and timely intervention before they escalate into critical failures.
By identifying and classifying these common types of IT incidents early, organizations can respond faster, reduce downtime, and maintain consistent service quality across their IT environments.
Importance of Incident Management for Businesses
Incident management plays a critical role in keeping businesses operational, resilient, and customer-focused. As organizations become increasingly dependent on digital systems and interconnected services, even minor disruptions can escalate quickly if not handled effectively.
A well-defined incident management process provides teams with a clear playbook to respond, communicate, collaborate, and recover—ensuring minimal disruption to both internal operations and external stakeholders.
Faster Problem Resolution
Effective incident management enables teams to identify, prioritize, and resolve issues quickly. With structured workflows, automation, and AI-driven tools, incidents are routed to the right teams without delay. This reduces constant firefighting, accelerates recovery, and allows teams to focus on strategic business activities rather than reactive troubleshooting.
Reduced Downtime and Business Disruption
Downtime directly impacts revenue, productivity, and customer trust. Incident management processes help organizations restore services faster by ensuring clear ownership, predefined escalation paths, and coordinated response efforts. Over time, well-documented procedures can significantly reduce or even eliminate avoidable downtime.
Improved User and Customer Experience
When incidents are resolved quickly and correctly, service quality improves. Incident management ensures users have clear channels to report issues and receive timely updates. Transparent, two-way communication throughout the incident lifecycle builds confidence, improves satisfaction scores, and strengthens long-term customer relationships.
Greater Operational Efficiency and Productivity
Incident management creates consistency in how issues are handled. Standardized processes, historical incident data, and performance metrics such as Mean Time to Resolution (MTTR) help organizations optimize workflows and continuously improve service delivery. As a result, support teams work more efficiently, and employees experience fewer disruptions.
Enhanced Visibility and Transparency
A centralized incident management system provides end-to-end visibility into incident status, severity, and impact. Employees and stakeholders can track progress from reporting to resolution, improving trust and accountability. This transparency also enhances the overall employee experience by reducing uncertainty during service disruptions.
SLA Compliance and Service Reliability
Service Level Agreements (SLAs) define expected response and resolution times. Incident management helps organizations monitor and meet these commitments by aligning incident prioritization with business impact. Consistent SLA performance not only avoids penalties but also reinforces service reliability and brand credibility.
Deeper Insights and Continuous Improvement
Each incident generates valuable data. By logging incident details, resolution steps, and outcomes, organizations gain insights into recurring issues, root causes, and service quality trends. These insights support better decision-making, predictive remediation, and the creation of playbooks for handling similar incidents in the future.
Prevention of Future Incidents
Incident management is not just reactive—it is preventive. By capturing incident forensics and identifying risks early, organizations can reduce incident recurrence over time. Knowledge bases, self-service portals, and AI-driven recommendations help deflect incidents before they impact users, strengthening overall system stability.
Better Collaboration Across Teams
Incident recovery often requires cross-functional collaboration. A structured incident management framework defines communication guidelines, roles, and responsibilities, enabling teams to work together more effectively under pressure. Clear coordination also helps manage stakeholder expectations and maintain alignment during high-impact incidents.
Improved Employee Experience
Smooth internal operations reflect directly on employee morale and productivity. When systems are reliable and incidents are resolved efficiently, employees face fewer disruptions in their daily work. Omnichannel support options—such as self-service portals, chatbots, and mobile access—further empower employees to report and track issues with ease.
In summary, incident management is not just an IT process—it is a business-critical capability. By reducing downtime, improving service quality, enabling data-driven improvements, and strengthening collaboration, effective incident management helps organizations remain resilient, competitive, and prepared for future disruptions.
Key Components of an Effective Incident Management Process
An effective incident management process is built on clearly defined components that work together to ensure incidents are handled quickly, consistently, and with minimal business impact. These components provide structure during high-pressure situations, enabling teams to respond decisively while maintaining service quality and stakeholder confidence.
Incident Identification and Detection
The first step in incident management is identifying when something goes wrong. Incidents may be detected through system monitoring tools, automated alerts, user reports, or service desk tickets. Early detection is critical, as faster identification reduces the likelihood of minor issues escalating into major service disruptions.
Incident Logging and Documentation
Once detected, incidents must be logged in a centralized system. Accurate documentation captures essential details such as time of occurrence, affected services, symptoms, and initial actions taken. This ensures traceability, supports compliance requirements, and creates a knowledge base for resolving future incidents more efficiently.
Categorization and Prioritization
Not all incidents carry the same level of urgency or impact. Categorization helps classify incidents based on type (e.g., application, network, security), while prioritization assesses business impact and urgency. This step ensures that critical incidents affecting core services or a large number of users are addressed first.
Incident Ownership and Escalation
Clear ownership is essential for accountability. Each incident should be assigned to a responsible individual or team who drives it toward resolution. When incidents exceed defined thresholds—such as severity, time, or complexity—escalation procedures ensure they are promptly routed to higher-level support or specialized teams.
Investigation and Diagnosis
During this phase, teams analyze the incident to identify the underlying issue and determine the best path to resolution. Effective investigation relies on collaboration, access to historical incident data, and diagnostic tools. The focus remains on restoring service quickly, even if the root cause analysis is completed later.
Resolution and Service Restoration
Resolution involves applying fixes or workarounds to restore affected services to their normal operating state. An incident is considered resolved once service functionality is restored and users can operate as intended. Speed and accuracy at this stage are critical to minimizing downtime and business disruption.
Communication and Stakeholder Updates
Consistent communication is a vital component of incident management. Stakeholders—including users, leadership, and service owners—must be kept informed about incident status, impact, and expected resolution timelines. Clear and timely updates help manage expectations and maintain trust during disruptions.
Incident Closure and Verification
Before closing an incident, teams verify that the service has been fully restored and that no residual issues remain. Proper closure includes updating records, confirming user satisfaction where applicable, and ensuring all actions taken are documented for future reference.
Post-Incident Review and Continuous Improvement
After resolution, a structured review helps teams learn from the incident. Post-incident analysis examines what happened, how it was handled, and what can be improved. These insights feed into process enhancements, preventive measures, and training—strengthening the organization’s ability to handle future incidents.
Together, these components form a comprehensive incident management process that not only restores services quickly but also builds long-term operational resilience and continuous improvement.
Three Core Priorities That Drive Effective Incident Management
When systems fail or services degrade, incident management teams act as the first line of defense—working to prevent a temporary disruption from escalating into a full-scale business crisis.
In high-pressure situations, success depends on focusing on a few clear priorities that guide decision-making, coordination, and execution. The following three priorities shape how teams respond when incidents occur.
Restore Service as Quickly as Possible
The foremost priority in incident management is to restore affected services fast. The immediate objective is not to find a perfect or permanent fix, but to stabilize operations so the business can continue functioning.
Teams may roll back recent changes, switch to backup systems, or temporarily disable problematic features to bring services back online. Rapid service restoration reduces downtime, protects revenue, and eases pressure while teams investigate the underlying cause.
Minimize Business and Customer Impact
While service recovery is underway, teams must also work to contain the incident and limit its reach. This involves isolating affected systems, rerouting traffic, or restricting certain functionalities to prevent the issue from spreading.
By reducing the “blast radius” of an incident, organizations can ensure that disruption is limited to a smaller group of users or services, preserving customer trust and operational stability.
Ensure Compliance and Responsible Response
Speed alone is not enough—incident response must also be responsible and compliant. Teams need to follow regulatory requirements, internal policies, and governance standards while managing incidents. This includes documenting actions taken, preserving logs, maintaining audit trails, and notifying stakeholders or regulators when required. A compliant response ensures transparency, reduces legal risk, and strengthens organizational credibility, especially in regulated industries.
Together, these three priorities—restoring service, minimizing impact, and remaining compliant—provide a clear framework for decision-making during incidents, helping teams act decisively without compromising accountability or long-term business integrity.
7 Key Steps in the Incident Management Process
An incident can occur without warning—but it doesn’t have to result in chaos. A clearly defined incident management process gives teams a reliable, repeatable way to respond when systems fail, performance degrades, or security threats emerge.
While organizations may tailor the workflow to their needs, the following seven steps form the foundation of most effective incident management frameworks and help ensure that small issues don’t escalate into major business disruptions.
1. Incident Detection
The incident management process begins with identifying that something is wrong. Incidents may be detected through automated monitoring tools, alerts, anomaly detection, simulated user testing, or user and customer reports.
Early detection is critical, as delayed awareness increases downtime and business impact. Proactive monitoring helps organizations identify issues before users experience them.
2. Incident Logging and Classification
Once detected, the incident must be logged in a centralized system. Logging captures essential details such as time of occurrence, affected systems, reported symptoms, and initial actions taken.
Classification then categorizes the incident by type and scope, helping teams understand its nature and determine the appropriate response path.
3. Categorization and Prioritization
Not all incidents require the same level of urgency. Categorization groups incidents based on affected services or systems, while prioritization assesses business impact and time sensitivity.
High-impact, business-critical incidents—such as payment failures or system outages—are addressed first, ensuring resources are focused where they matter most and SLA commitments are met.
4. Incident Assignment and Containment
After prioritization, incidents are assigned to the most appropriate team or specialist. Correct assignment prevents delays caused by misrouting.
At the same time, teams focus on containment—isolating affected components, rerouting traffic, or limiting functionality—to prevent the issue from spreading and reduce disruption to users and operations.
5. Investigation and Diagnosis
This step focuses on identifying the underlying cause of the incident. Teams analyze logs, system behavior, recent changes, and historical data to determine why the issue occurred.
Techniques such as root cause analysis, issue replication, and AI-assisted diagnostics help accelerate this phase and avoid time-consuming guesswork.
6. Resolution and Service Recovery
Resolution involves implementing fixes or workarounds to restore services safely and quickly. This may include rolling back deployments, applying patches, updating configurations, or activating backup systems. After deployment, teams validate that services are stable and monitor systems to ensure the issue does not reoccur.
7. Incident Closure and Post-Incident Review
An incident is closed only after services are fully restored and verified. Teams document the resolution steps, confirm that temporary fixes are removed, and communicate closure to stakeholders. A post-incident review then analyzes what happened, what worked, and what can be improved—turning the incident into a learning opportunity that strengthens future response and prevention efforts.
Together, these seven steps create a structured incident management lifecycle that enables faster recovery, reduced downtime, continuous improvement, and greater organizational resilience.
Common Challenges in Incident Management
Even with well-defined processes, incident management can be difficult to execute consistently in fast-paced IT environments. Growing system complexity, rising user expectations, and limited resources often expose gaps in how incidents are detected, handled, and resolved.
Below are some of the most common challenges organizations face when managing incidents.
Alert Fatigue and Poor Signal-to-Noise Ratio
Teams are often overwhelmed by a high volume of alerts, many of which are low priority or false positives. This makes it harder to identify critical incidents quickly and can delay response times when real issues occur.
Lack of Clear Ownership and Accountability
When roles and responsibilities are not clearly defined, incidents can stall as teams debate who should take charge. This lack of ownership increases resolution time and can lead to inconsistent handling of similar incidents.
Slow Detection and Delayed Response
Without proper monitoring and escalation mechanisms, incidents may go unnoticed for long periods. Delayed detection directly impacts mean time to respond and increases the overall business impact of an outage.
Inadequate Root Cause Analysis
Many teams focus on restoring services quickly but fail to investigate why the incident happened in the first place. As a result, the same issues resurface, increasing incident recurrence and long-term operational risk.
Poor Communication During Incidents
Ineffective communication between IT teams, stakeholders, and end users can create confusion and frustration. Missing or inconsistent updates often make incidents feel more severe than they actually are.
Limited Automation and Over-Reliance on Manual Processes
Manual incident handling slows down response times and increases the risk of human error. Teams that lack automation struggle to scale their incident management processes as systems grow more complex.
Tool Fragmentation and Lack of Integration
Using multiple disconnected tools for monitoring, ticketing, and communication leads to data silos. This fragmentation reduces visibility, makes coordination harder, and complicates post-incident analysis.
Difficulty Measuring Incident Management Performance
Without clearly defined metrics and consistent tracking, it becomes hard to assess how effective incident management efforts really are. This limits an organization’s ability to justify improvements or demonstrate progress over time.
Addressing these challenges requires not just better tools, but stronger processes, clearer accountability, and a continuous focus on learning from every incident.
Incident Management Best Practices
A well-designed incident management process is only effective when it is consistently supported by best practices. These practices help organizations respond faster, reduce disruption, improve collaboration, and continuously strengthen service reliability. By embedding the following principles into daily operations, teams can handle incidents more calmly and predictably—even under pressure.
Log Everything in a Single System
Every incident, regardless of severity or source, should be logged in one centralized tool. Comprehensive logging ensures nothing is overlooked, speeds up response times, and creates a reliable historical record. Automated logging and reconciliation further improve accuracy and consistency.
Capture Complete and Accurate Details
Incomplete records slow down investigations and limit learning. Teams should document all relevant details, including timelines, affected systems, observed symptoms, actions taken, and outcomes. Thorough documentation supports root cause analysis, reporting, and compliance requirements.
Keep Categorization Simple and Consistent
Overly complex categories and vague options like “other” reduce clarity and delay response. Clean, well-defined categories help incidents route to the right teams quickly and ensure accurate prioritization and reporting.
Standardize Processes Across Teams
Consistency is critical during high-stress incidents. Standardized procedures ensure every team member follows the same steps, uses approved responses, and maintains service quality. Shared playbooks and runbooks help reduce confusion and variability in incident handling.
Reuse Proven Solutions and Knowledge
Not every incident requires a new fix. Leveraging documented solutions, known workarounds, and knowledge base articles helps resolve incidents faster and keeps responses consistent across teams.
Train and Empower Employees
Effective incident management is a team effort. Regular training ensures IT teams stay prepared, while basic incident response training for non-IT staff helps reduce noise and allows specialists to focus on high-priority issues. Well-trained teams collaborate better and communicate more clearly during incidents.
Set Clear Alerts and On-Call Structures
Alert fatigue can be as damaging as missed alerts. Define meaningful thresholds, service level indicators, and escalation rules to ensure the right incidents trigger the right responses. Clear on-call schedules ensure qualified responders are available without overwhelming individuals.
Establish Clear Communication Guidelines
Communication breakdowns often worsen incidents. Define which channels to use, what information should be shared, and how updates are documented. Clear guidelines reduce stress, prevent misinformation, and ensure stakeholders stay informed throughout the incident lifecycle.
Streamline Change Management During Incidents
Emergency fixes often require changes under pressure. Predefine what changes can be made, who can approve them, and how quickly approvals must happen. Streamlined change processes prevent delays while maintaining control and accountability.
Leverage Automation and AI
Automation accelerates ticket creation, routing, notifications, and repetitive tasks, reducing manual effort and human error. AI-driven tools can assist with categorization, root cause detection, and recommended actions—significantly improving response and resolution times.
Conduct Root Cause Analysis and Post-Incident Reviews
Resolution is not the end of incident management. Structured post-incident reviews help teams understand what went wrong, identify preventive measures, and refine processes. A blameless culture encourages honest reflection and continuous improvement.
Test Resilience Through Drills and Simulations
Regular incident simulations and chaos engineering practices expose weaknesses before real incidents occur. These exercises strengthen response capabilities, improve coordination, and ensure teams are ready when real disruptions happen.
By following these incident management best practices, organizations can move beyond reactive firefighting to a mature, resilient approach—one that minimizes downtime, improves service quality, and continuously strengthens operational readiness.
Metrics That Define Successful Incident Management
Tracking the right performance metrics allows teams to continuously improve their incident response and demonstrate the business value of incident management.
- Mean Time to Detect (MTTD) measures how quickly teams become aware of an issue after it occurs, reflecting monitoring and alerting effectiveness.
- Mean Time to Respond (MTTR) tracks the average time taken to resolve an incident once it has been identified, highlighting operational efficiency.
- First Contact Resolution (FCR) rate indicates how often incidents are resolved during the initial interaction without escalation.
- Incident volume monitors the number of incidents over a specific period, helping identify trends, system instability, or emerging risks.
- Incident recurrence rate reveals whether similar incidents continue to occur, signaling unresolved root causes.
- Customer Satisfaction (CSAT) captures user perception of the resolution experience, typically through post-incident surveys.
- Service Level Agreement (SLA) compliance rate measures how consistently response and resolution commitments are met.
When tracked consistently, these metrics provide clear insights into process maturity, highlight improvement areas, and help teams confidently communicate the effectiveness of their incident management strategy.
Future Trends in Incident Management
Incident management is evolving rapidly as organizations face increasingly complex IT environments, higher uptime expectations, and stricter compliance requirements. Future-ready incident management is shifting from reactive firefighting to predictive, automated, and intelligence-driven operations.
The following trends are shaping how modern teams detect, respond to, and learn from incidents.
AI-Driven Incident Detection and Resolution
Artificial intelligence and machine learning are playing a growing role in identifying anomalies before they escalate into major incidents. Advanced systems can correlate alerts across applications, infrastructure, and networks to reduce noise and surface true incidents faster. In many cases, AI can also recommend or trigger automated remediation steps, significantly reducing response times.
Increased Automation and Self-Healing Systems
Automation is moving beyond ticket creation to full incident resolution. Self-healing systems can automatically restart services, reroute traffic, or roll back faulty deployments without human intervention. This trend helps organizations restore services faster while freeing IT teams to focus on strategic problem-solving rather than repetitive tasks.
Shift Toward Predictive Incident Management
Instead of responding only after failures occur, organizations are using historical incident data and performance analytics to predict potential disruptions. Predictive models help teams identify weak points, plan preventive maintenance, and reduce incident frequency, improving overall service reliability.
Deeper Integration with DevOps and SRE Practices
Incident management is becoming tightly integrated with DevOps and Site Reliability Engineering (SRE). Real-time feedback from incidents is feeding directly into development and release cycles, enabling faster fixes and more resilient system design. Post-incident reviews are also becoming more structured and data-driven, strengthening continuous improvement.
Greater Focus on User Experience and Business Impact
Future incident management frameworks are prioritizing business impact over technical severity alone. Teams are increasingly measuring how incidents affect customers, revenue, and productivity. This shift ensures that response efforts align with what matters most to the business and end users, not just system metrics.
Stronger Compliance, Governance, and Audit Readiness
As regulatory requirements grow, incident management processes are being designed with compliance in mind. Automated documentation, clear audit trails, and standardized response workflows help organizations remain transparent and accountable, even during high-pressure incidents.
Unified Incident Management Across Hybrid Environments
With the rise of hybrid and multi-cloud environments, incident management tools are evolving to provide a single, unified view across on-premise systems, cloud platforms, and third-party services. Centralized visibility and coordination are becoming essential to manage incidents effectively in distributed ecosystems.
Together, these trends signal a future where incident management is faster, smarter, and more proactive—helping organizations maintain stability, protect customer trust, and support long-term digital resilience.
How Deskera ERP Can Help With Incident Management
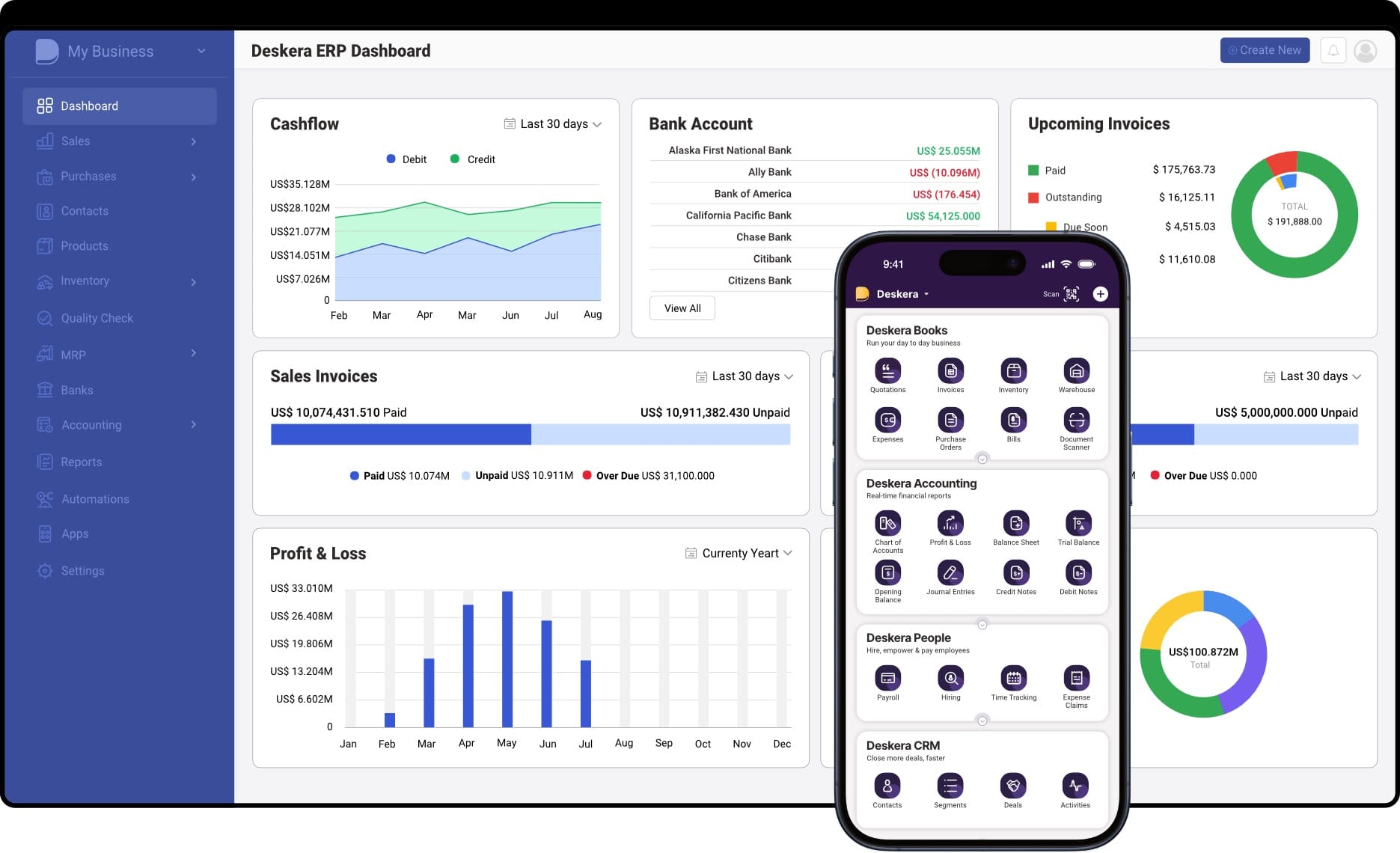
Although Deskera ERP is not a standalone ITSM platform, it provides practical capabilities that support incident handling through structured support workflows and automation.
Centralized Support and Ticket Management
Deskera includes a built-in customer service and helpdesk module within its ERP suite, enabling organizations to manage incidents and service disruptions in a centralized system. Teams can log user- or customer-reported issues as tickets, track interactions in one place, and follow each case through to resolution. This structured ticketing approach ensures incidents are documented, assigned, and monitored consistently, reducing the risk of issues being overlooked.
Workflow Automation for Faster Response
Deskera supports workflow automation that helps streamline how incidents are handled. Incoming issues—such as support emails or customer queries—can be automatically converted into tickets and routed to the appropriate team. Task assignments, status updates, and follow-ups can be managed within predefined workflows, helping teams respond more quickly and maintain accountability during resolution.
Task Ownership and Performance Tracking
By assigning tickets to specific owners and tracking response activity, Deskera helps teams monitor how effectively incidents are being handled. Managers can review response performance, identify delays, and ensure service commitments are being met, supporting continuous improvement in incident handling processes.
Structured Handling of Service Requests and Disruptions
Treating disruptions and service issues as tickets allows organizations to apply consistent processes across departments. This structured approach improves visibility, supports better coordination, and lays the groundwork for analyzing recurring issues that may require deeper investigation or process changes.
Key Takeaways
- Incident management is essential for maintaining service continuity, minimizing downtime, and protecting customer trust in increasingly complex digital environments.
- A well-defined incident management process enables teams to respond quickly, contain impact, and restore services without creating additional operational risk.
- Prioritizing rapid service restoration, impact reduction, and compliance ensures that teams act decisively while maintaining accountability under pressure.
- Understanding common IT incidents—such as hardware failures, software bugs, security breaches, and human errors—helps organizations prepare targeted response strategies.
- Clear categorization and differentiation between incidents, problems, changes, and service requests improves response accuracy and prevents process confusion.
- Adopting best practices like centralized logging, standardized workflows, automation, and post-incident reviews strengthens process maturity over time.
- Tracking key metrics such as MTTD, MTTR, SLA compliance, and incident recurrence provides measurable insight into incident management effectiveness.
- Emerging trends like automation, AI-assisted workflows, and proactive monitoring are reshaping how organizations detect and resolve incidents.
- Despite common challenges such as communication gaps, alert fatigue, and resource constraints, structured processes and clear ownership significantly improve outcomes.
- Tools like Deskera can support incident management through centralized ticketing, workflow automation, and performance visibility, helping teams handle disruptions in a more organized and consistent manner.
Related Articles








